V-STaR : Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning

Abstract
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.
Leaderboard
Benchmark Statistics
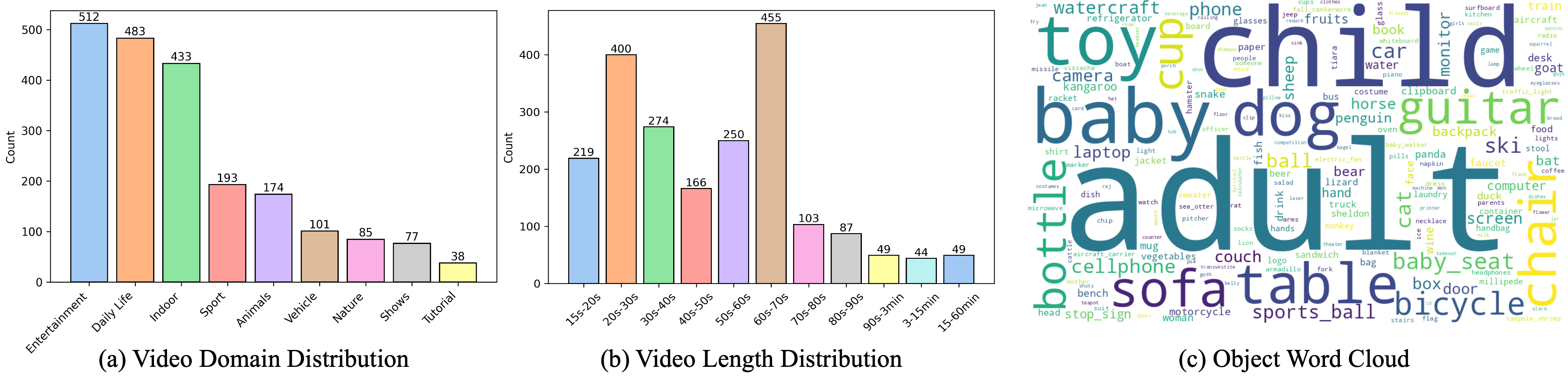
Dataset statistics of video domain and length, and word cloud of objects in video.
V-STaR evaluation results of each domain
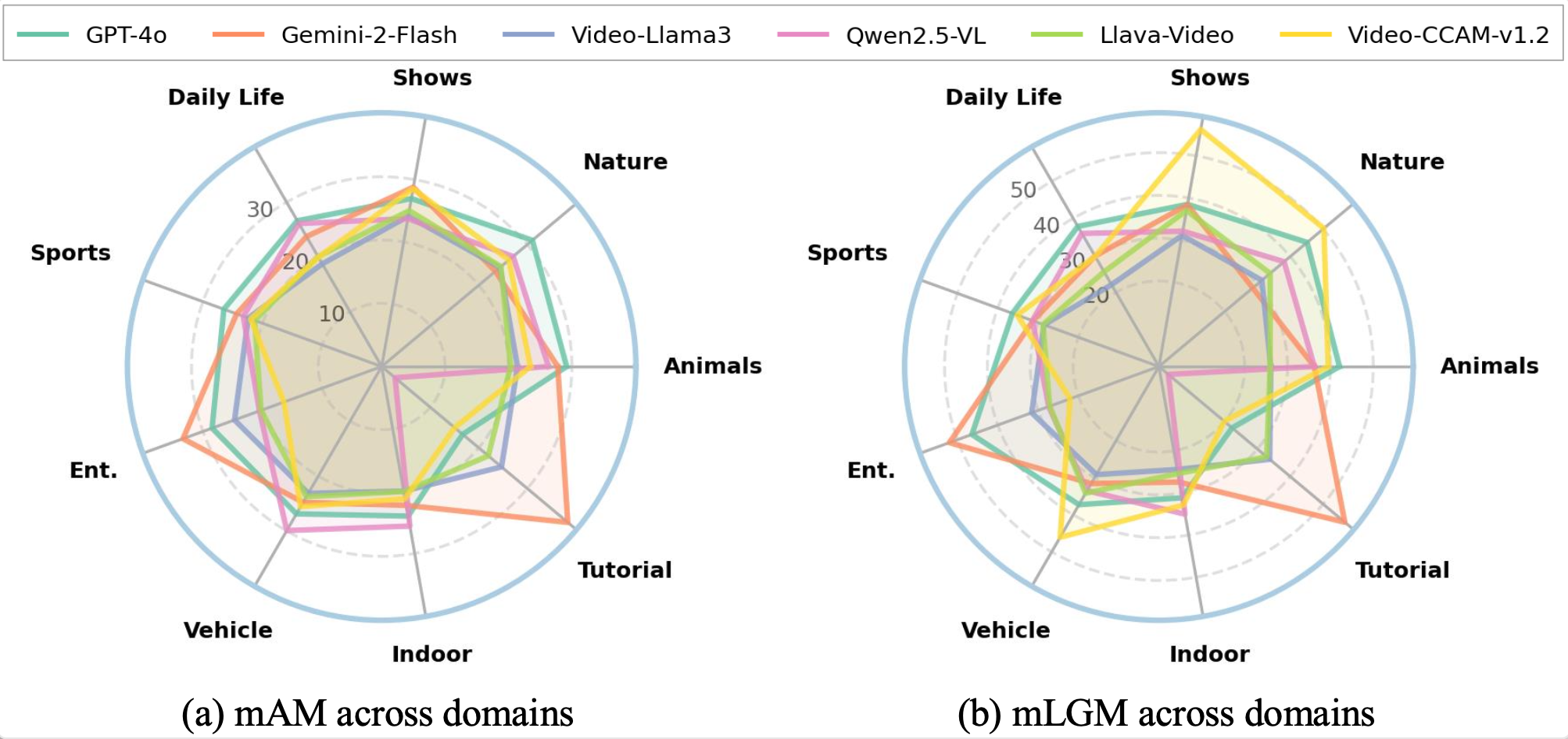
We visualize the performance on each domain across 9 domains using mAM (left) and mLGM (right).
Qualitative Analysis 1
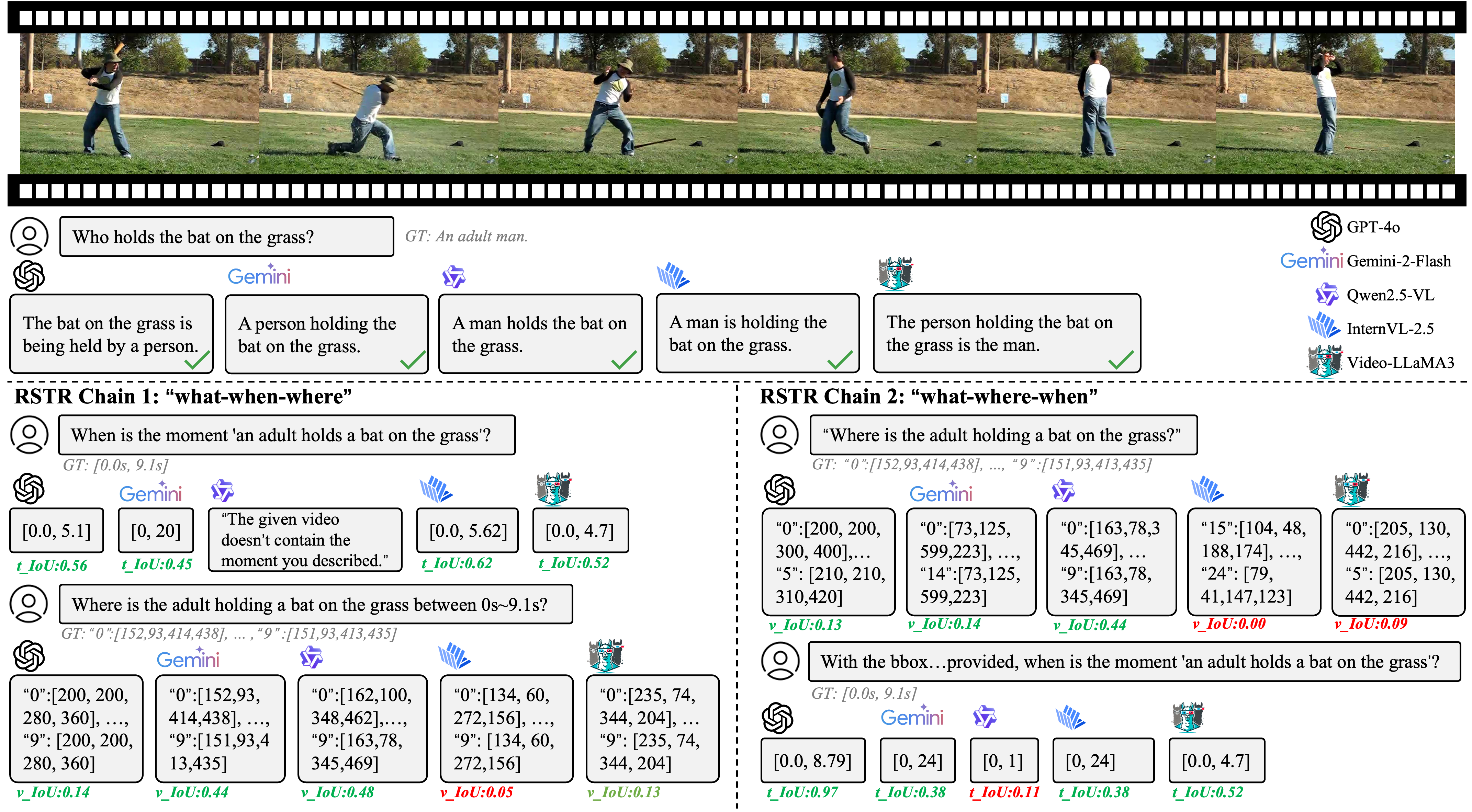
An example showcasing the performance of five models on the video sourced from VidSTG.
Qualitative Analysis 2
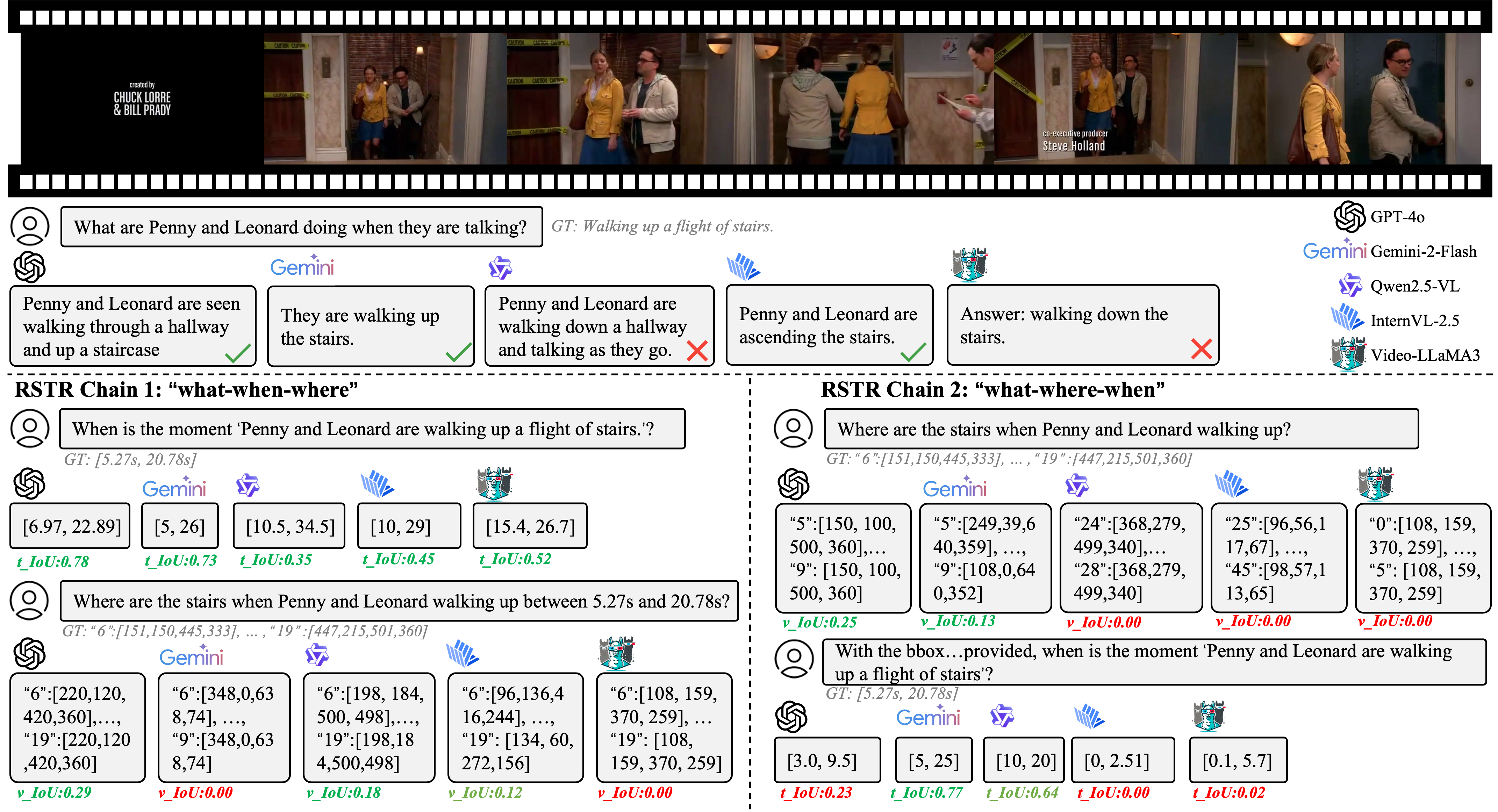
An example showcasing the performance of five models on the video sourced from TVQA+.
Qualitative Analysis 3
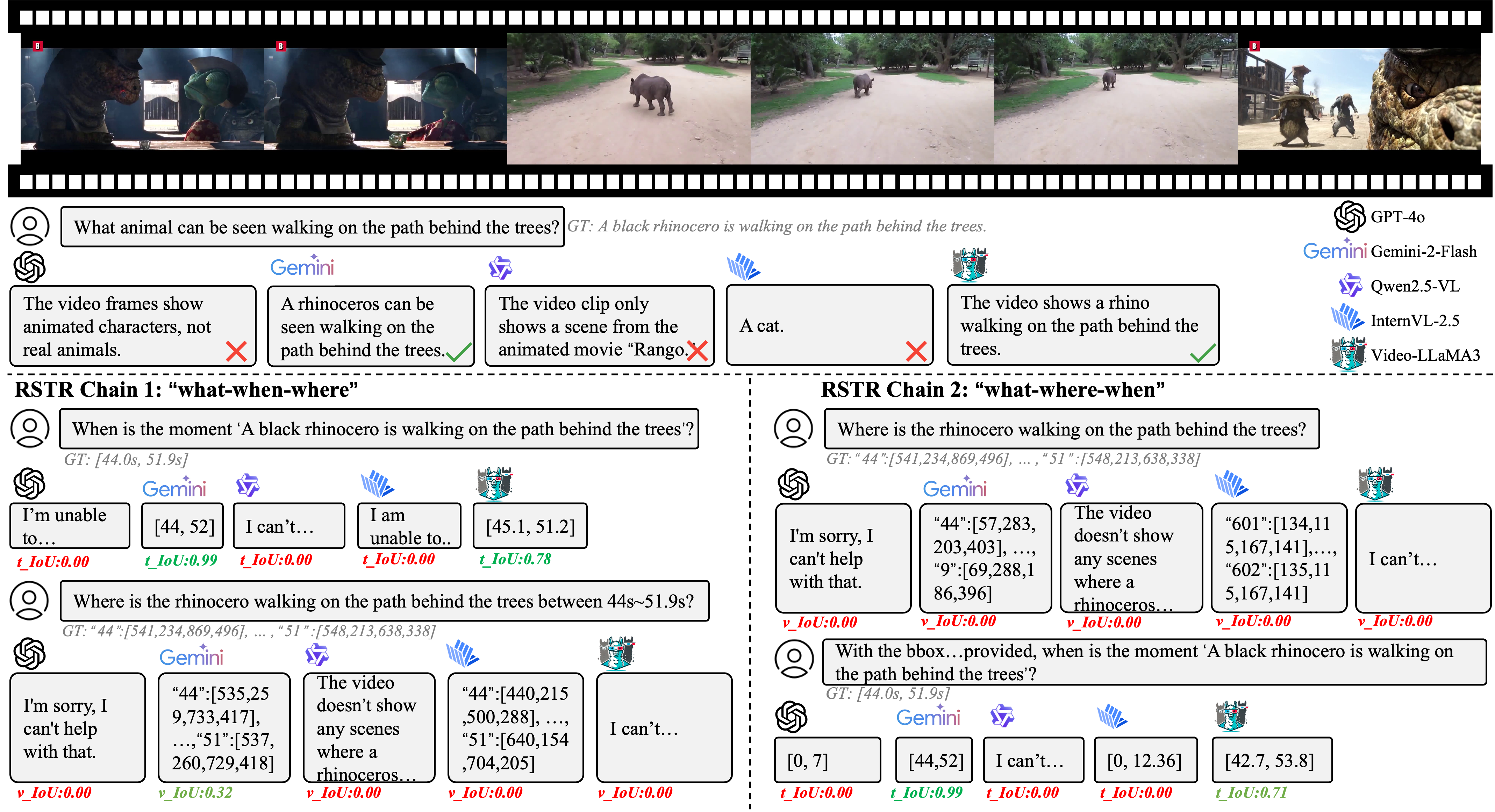
An example showcasing the performance of five models on the video sourced from GOT-10k.
BibTeX
If you find our work useful, please consider citing our paper:
@misc{cheng2025vstarbenchmarkingvideollmsvideo,
title={V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning},
author={Zixu Cheng and Jian Hu and Ziquan Liu and Chenyang Si and Wei Li and Shaogang Gong},
year={2025},
eprint={2503.11495},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.11495},
}